
# webpack 精选面试题
# 有哪些常见的Loader?你用过哪些Loader?
# Webpack构建流程简单说一下
初始化参数:从配置文件和 Shell 语句中读取与合并参数,得出最终的参数
开始编译:用上一步得到的参数初始化 Compiler 对象,加载所有配置的插件,执行对象的 run 方法开始执行编译
确定入口:根据配置中的 entry 找出所有的入口文件
编译模块:从入口文件出发,调用所有配置的 Loader 对模块进行翻译,再找出该模块依赖的模块,再递归本步骤直到所有入口依赖的文件都经过了本步骤的处理
完成模块编译:在经过第4步使用 Loader 翻译完所有模块后,得到了每个模块被翻译后的最终内容以及它们之间的依赖关系
输出资源:根据入口和模块之间的依赖关系,组装成一个个包含多个模块的 Chunk,再把每个 Chunk 转换成一个单独的文件加入到输出列表,这步是可以修改输出内容的最后机会
输出完成:在确定好输出内容后,根据配置确定输出的路径和文件名,把文件内容写入到文件系统
在以上过程中,Webpack 会在特定的时间点广播出特定的事件,插件在监听到感兴趣的事件后会执行特定的逻辑,并且插件可以调用 Webpack 提供的 API 改变 Webpack 的运行结果。
简单说:
初始化:启动构建,读取与合并配置参数,加载 Plugin,实例化 Compiler
编译:从 Entry 出发,针对每个 Module 串行调用对应的 Loader 去翻译文件的内容,再找到该 Module 依赖的 Module,递归地进行编译处理
输出:将编译后的 Module 组合成 Chunk,将 Chunk 转换成文件,输出到文件系统中
# webpack中如何处理图片的?
在webpack中有两种处理图片的loader:
file-loader:解决 CSS 等中引入图片的路径问题;(解决通过 url,import/require()等引入图片的问题)
url-loader:当图片小于设置的 limit 参数值时,url-loader 将图片进行 base64 编码(当项目中有很多图片,通过 url-loader 进行 base64 编码后会减少 http 请求数量,提高性能),大于 limit 参数值,则使用 file-loader 拷贝图片并输出到编译目录中
# 使用webpack开发时,你用过哪些可以提高效率的插件?
webpack-dashboard:可以更友好的展示相关打包信息
webpack-merge:提取公共配置,减少重复配置代码
speed-measure-webpack-plugin:简称 SMP,分析出 Webpack 打包过程中 Loader 和 Plugin 的耗时,有助于找到构建过程中的性能瓶颈
webpack-bundle-analyzer 分析打包后的文件
HotModuleReplacementPlugin:模块热替换
# source map 是什么?生产环境怎么用?
source map 是将编译、打包、压缩后的代码映射回源代码的过程。打包压缩后的代码不具备良好的可读性,想要调试源码就需要 soucre map。
map文件只要不打开开发者工具,浏览器是不会加载的。
线上环境一般有三种处理方案:
hidden-source-map:借助第三方错误监控平台 Sentry 使用
nosources-source-map:只会显示具体行数以及查看源代码的错误栈。安全性比 sourcemap 高
sourcemap:通过 nginx 设置将 .map 文件只对白名单开放(公司内网)
注意:避免在生产中使用 inline- 和 eval-,因为它们会增加 bundle 体积大小,并降低整体性能。
开发环境推荐: cheap-module-eval-source-map
生产环境推荐: cheap-module-source-map
# 如何对bundle体积进行监控和分析?
VSCode 中有一个插件 Import Cost 可以帮助我们对引入模块的大小进行实时监测,还可以使用 webpack-bundle-analyzer 生成 bundle 的模块组成图,显示所占体积。
bundlesize 工具包可以进行自动化资源体积监控。
# 在实际工程中,配置文件上百行乃是常事,如何保证各个loader按照预想方式工作?
可以使用 enforce 强制执行 loader 的作用顺序,pre 代表在所有正常 loader 之前执行,post 是所有 loader 之后执行。(inline 官方不推荐使用)
# webpack打包速度太慢怎么办?如何优化 Webpack 的构建速度?
加快构建速度(打包速度)
使用 speed-measure-webpack-plugin 插件可以测量各个插件和loader所花费的时间,量化打包速度,判断优化效果
- 缩小文件的搜索范围(配置include/exclude resolve.modules resolve.mainFields alias noParse extensions)
- 通过 exclude、include 配置来确保转译尽可能少的文件
- 优化 resolve.modules 配置
- 优化 resolve.mainFields 配置
- alias
- noParse
- extensions
- 在一些性能开销较大的 loader 之前添加 cache-loader,将结果缓存中磁盘中
- 使用 happypack 开启多进程打包
- 除了使用 Happypack 外,我们也可以使用 thread-loader 开启多进程打包 loader TerserWebpackPlugin
- 使用 HardSourceWebpackPlugin 为模块提供中间缓存,第二次构建可大量节约时间
- 使用 IgnorePlugin 忽略第三方包指定目录,例如 moment 的本地语言包
- 使用 webpack-parallel-uglify-plugin 开启 JS 多进程压缩
减少打包文件体积
引入 webpack-bundle-analyzer 分析打包后的文件,判断哪些包还可以拆分和优化
- 使用 externals 配置,然后将 JS 文件、CSS 文件和存储在 CDN
- 使用 DllPlugin(动态链接库)将 bundles 拆分,使用 DllReferencePlugin(索引链接) 对 manifest.json 引用,让一些基本不会改动的代码先打包成静态资源,避免反复编译浪费时间
- 使用 optimization.splitChunks 配置抽离公共代码
- 使用 IgnorePlugin 忽略第三方包指定目录,例如 moment 的本地语言包(重复)
- 使用 url-loader 或 image-webpack-loader 对图片进行转化或者压缩处理
- 优化 SourceMap,开发环境推荐: cheap-module-eval-source-map,生产环境推荐: cheap-module-source-map
- 按需加载,项目中的路由懒加载
- webpack自身的优化:
- tree-shaking,在生产环境下,会自动移除没有使用到的代码
- scope hosting 作用域提升,变量提升,可以减少一些变量声明
- babel 配置的优化,配置 @babel/plugin-transform-runtime,重复使用 Babel 注入的帮助程序,以节省代码大小的插件。
更多请参考官网构建性能 (opens new window)
# webpack如果使用了hash命名,那是每次都会重写生成hash吗?
要看webpack的配置(文件指纹,通过 output 中的 filename 设置),有三种情况:
- 如果是 hash 的话,是和整个项目有关的,有一处文件发生更改则所有文件的hash值都会发生改变且它们共用一个 hash 值;
- 如果是 chunkhash 的话,只和 entry 的每个入口文件有关,也就是同一个 chunk 下的文件有所改动该 chunk 下的文件的 hash 值就会发生改变
- 如果是 contenthash 的话,和每个生成的文件有关,只有当要构建的文件内容发生改变时才会给该文件生成新的 hash 值,并不会影响其它文件。
module.exports = {
entry: {
app: './scr/app.js',
search: './src/search.js'
},
output: {
filename: '[name][chunkhash:8].js',
path:__dirname + '/dist'
},
// 通过 MiniCssExtractPlugin 插件设置 css 文件指纹
plugins:[
new MiniCssExtractPlugin({
filename: `[name][contenthash:8].css`
})
],
module:{
// 通过 rules 配置图片的文件指纹设置
// 设置file-loader的name,使用hash。
rules:[{
test:/\.(png|svg|jpg|gif)$/,
use:[{
loader:'file-loader',
options:{
name:'img/[name][hash:8].[ext]'
}
}]
}]
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# 模块打包原理知道吗?
Webpack 实际上为每个模块创造了一个可以导出和导入的环境,本质上并没有修改 代码的执行逻辑,代码执行顺序与模块加载顺序也完全一致。
# 文件监听原理呢?
在发现源码发生变化时,自动重新构建出新的输出文件。
Webpack开启监听模式,有两种方式:
- 启动 webpack 命令时,带上 --watch 参数
- 在配置 webpack.config.js 中设置 watch:true
缺点:每次需要手动刷新浏览器
原理:轮询判断文件的最后编辑时间是否变化,如果某个文件发生了变化,并不会立刻告诉监听者,而是先缓存起来,等 aggregateTimeout 后再执行。
module.export = {
// 默认false,也就是不开启
watch: true,
// 只有开启监听模式时,watchOptions才有意义
watchOptions: {
// 默认为空,不监听的文件或者文件夹,支持正则匹配
ignored: /node_modules/,
// 监听到变化发生后会等300ms再去执行,默认300ms aggregateTimeout:300,
// 判断文件是否发生变化是通过不停询问系统指定文件有没有变化实现的,默认每秒问1000次
poll:1000
}
}
2
3
4
5
6
7
8
9
10
11
12
# 说一下 Webpack 的热更新原理吧
Webpack 的热更新又称热替换(Hot Module Replacement),缩写为 HMR。 这个机制可以做到不用刷新浏览器而将新变更的模块替换掉旧的模块
HMR的核心就是客户端从服务端拉去更新后的文件,准确的说是 chunk diff (chunk 需要更新的部分),实际上 WDS 与浏览器之间维护了一个 Websocket,当本地资源发生变化时,WDS(webpack-dev-server) 会向浏览器推送更新,并带上构建时的 hash,让客户端与上一次资源进行对比。客户端对比出差异后会向 WDS 发起 Ajax 请求来获取更改内容(文件列表、hash),这样客户端就可以再借助这些信息继续向 WDS 发起 jsonp 请求获取该chunk的增量更新。
后续的部分(拿到增量更新之后如何处理?哪些状态该保留?哪些又需要更新?)由 HotModulePlugin 来完成,提供了相关 API 以供开发者针对自身场景进行处理,像react-hot-loader 和 vue-loader 都是借助这些 API 实现 HMR。
细接请参考Webpack HMR 原理解析 (opens new window)
# 代码分割的本质是什么?有什么意义呢?
代码分割的本质其实就是在源代码直接上线和打包成唯一脚本 main.bundle.js 这两种极端方案之间的一种更适合实际场景的中间状态。
源代码直接上线:虽然过程可控,但是http请求多,性能开销大。
打包成唯一脚本:一把梭完自己爽,服务器压力小,但是页面空白期长,用户体验不好。
# webpack中的 loader 和 plugin 有什么区别?
loader 它是一个转换器,只专注于转换文件这一个领域,完成压缩、打包、语言编译,它仅仅是为了打包。并且运行在打包之前。Loader 本质就是一个函数,在该函数中对接收到的内容进行转换,返回转换后的结果。 因为 Webpack 只认识 JavaScript,所以 Loader 就成了翻译官,对其他类型的资源进行转译的预处理工作。
而 plugin 是一个扩展器,它丰富了 webpack 本身,为其进行一些其它功能的扩展。它不局限于打包,资源的加载,还有其它的功能。所以它是在整个编译周期都起作用。
# webpack手写loader会吗
loader 的 API (opens new window)
loader 从本质上来说其实就是一个函数(webpack里是一个node模块)。将相关类型的文件代码(code)给它,根据我们设置的规则,经过它的一系列加工处理后还给我们加工好的代码。
loader 编写原则:
- 单一原则: 每个 Loader 只做一件事;
- 链式调用: Webpack 会按顺序链式调用每个 Loader;
- 统一原则: 遵循 Webpack 制定的设计规则和结构,输入(UTF-8 格式编码)与输出均为字符串,各个 Loader 完全独立,即插即用;
Loader 运行在 Node.js 中,我们可以调用任意 Node.js 自带的 API 或者安装第三方模块进行调用。
加载本地 Loader 方法:
- Npm link
- ResolveLoader
案例:把 JavaScript 代码中的注释语法去除的 loader:
将 // @require '../style/index.css' 转换成 require('../style/index.css');
function replace(source) {
// 使用正则把 // @require '../style/index.css' 转换成 require('../style/index.css');
return source.replace(/(\/\/ *@require) +(('|").+('|")).*/, 'require($2);');
}
module.exports = function (content) {
return replace(content);
};
2
3
4
5
6
7
8
# 项目中有写过plugin么?原理?
webpack 在运行的生命周期中会广播出许多事件,Plugin 可以监听这些事件,在特定的阶段钩入想要添加的自定义功能。Webpack 的 Tapable 事件流机制保证了插件的有序性,使得整个系统扩展性良好。
Webpack 可以认为是一种基于事件流的编程范例,内部的工作流程都是基于插件机制串接起来。而将这些插件粘合起来的就是 webpack 自己实现的基础类 Tapable,plugin 方法就是该类暴露出来的,核心的对象 Compiler、Compilation 等都是继承于该对象(Tapable)。
compiler 暴露了和 Webpack 整个生命周期相关的钩子
compilation 暴露了与模块和依赖有关的粒度更小的事件钩子
compiler 和 compilation 的区别在于: compiler 代表了整个 webpack 从启动到关闭的生命周期,而 compilation 只是代表了一次新的编译过程
插件需要在其原型上绑定 apply 方法,才能访问 compiler 实例
传给每个插件的 compiler 和 compilation 对象都是同一个引用,若在一个插件中修改了它们身上的属性,会影响后面的插件
找出合适的事件点去完成想要的功能
- emit 事件发生时,可以读取到最终输出的资源、代码块、模块及其依赖,并进行修改(emit 事件是修改 Webpack 输出资源的最后时机)
- watch-run 当依赖的文件发生变化时会触发
异步的事件需要在插件处理完任务时调用回调函数通知 Webpack 进入下一个流程,不然会卡住
案例:在 Webpack 即将退出时再附加一些额外的操作,例如在 Webpack 成功编译和输出了文件后执行发布操作把输出的文件上传到服务器。 同时该插件还能区分 Webpack 构建是否执行成功。使用该插件时方法如下:
module.exports = {
plugins:[
// 在初始化 EndWebpackPlugin 时传入了两个参数,分别是在成功时的回调函数和失败时的回调函数;
new EndWebpackPlugin(() => {
// Webpack 构建成功,并且文件输出了后会执行到这里,在这里可以做发布文件操作
}, (err) => {
// Webpack 构建失败,err 是导致错误的原因
console.error(err);
})
]
}
2
3
4
5
6
7
8
9
10
11
要实现该插件,需要借助两个事件:
- done:在成功构建并且输出了文件后,Webpack 即将退出时发生;
- failed:在构建出现异常导致构建失败,Webpack 即将退出时发生; 实现该插件非常简单,完整代码如下:
class EndWebpackPlugin {
constructor(doneCallback, failCallback) {
// 存下在构造函数中传入的回调函数
this.doneCallback = doneCallback;
this.failCallback = failCallback;
}
apply(compiler) {
compiler.plugin('done', (stats) => {
// 在 done 事件中回调 doneCallback
this.doneCallback(stats);
});
compiler.plugin('failed', (err) => {
// 在 failed 事件中回调 failCallback
this.failCallback(err);
});
}
}
// 导出插件
module.exports = EndWebpackPlugin;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 聊一聊Babel原理吧
大多数JavaScript Parser遵循 estree 规范,Babel 最初基于 acorn 项目(轻量级现代 JavaScript 解析器) Babel大概分为三大部分:
解析:将代码转换成 AST
- 词法分析:将代码(字符串)分割为token流,即语法单元成的数组
- 语法分析:分析token流(上面生成的数组)并生成 AST
转换:访问 AST 的节点进行变换操作生产新的 AST
- Taro就是利用 babel 完成的小程序语法转换
生成:以新的 AST 为基础生成代码
Babel 的架构(图片来自深入浅出 Babel 上篇:架构和原理 + 实战 (opens new window)):
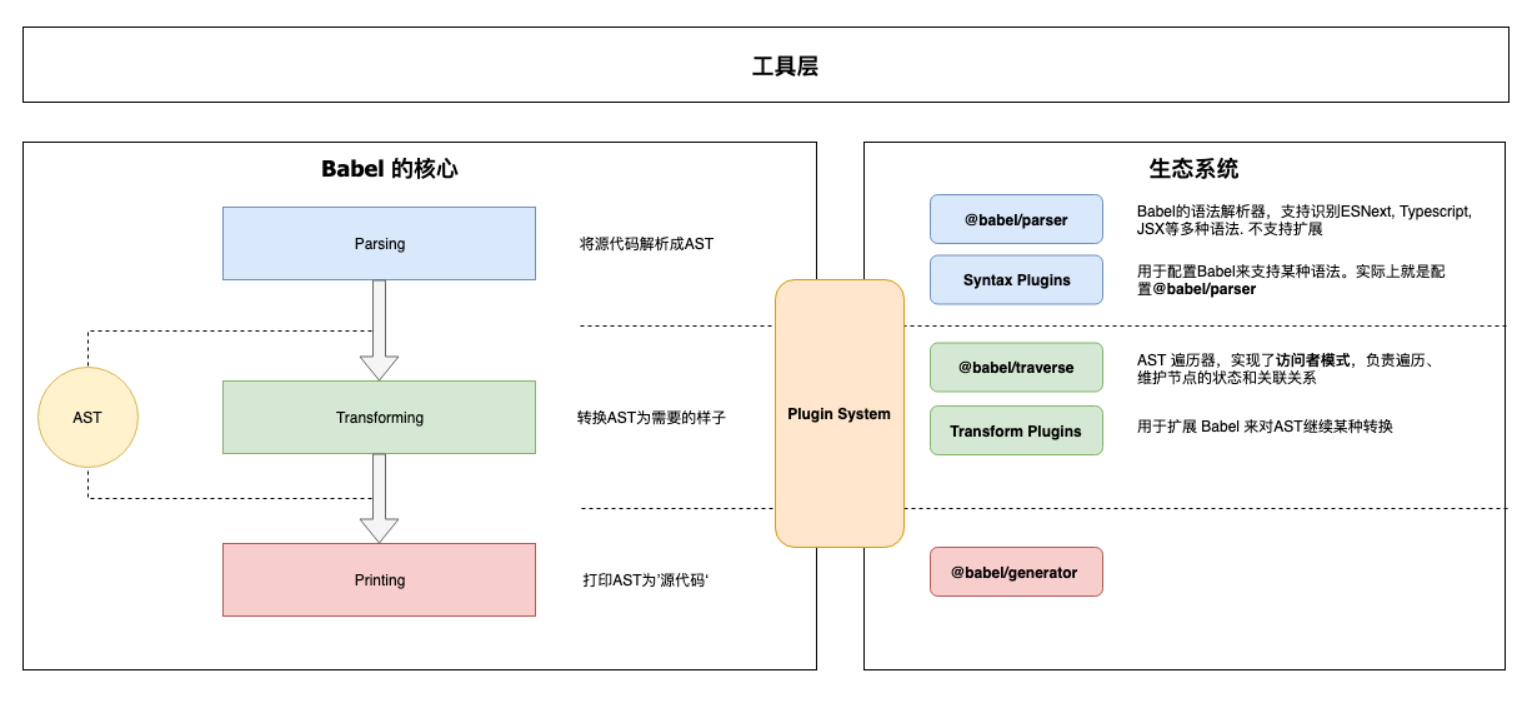
想了解如何一步一步实现一个编译器的同学可以移步 Babel 官网曾经推荐的开源项目 the-super-tiny-compiler (opens new window)
# 什么是 AST(抽象语法树)
AST 通俗的来说,假设我们有一个文件 a.js,我们对 a.js 里面的 1000 行进行一些操作处理,比如为所有的 await 增加t ry catch,以及其他操作,但是 a.js 里面的代码本质上来说就是一堆字符串。那我们怎么办呢,那就是转换为带标记信息的对象(抽象语法树)我们方便进行增删改查。这个带标记的对象(抽象语法树)就是 AST。这里推荐一篇不错的 AST 文章 AST快速入门 (opens new window)
比如我们自己实现一个 loader 去除代码中的 console,我们就需要把代码转换成 AST 然后标记去除 console 后再解码生成 js 代码:
npm i -D @babel/parser @babel/traverse @babel/generator @babel/types
- @babel/parser 将源代码解析成 AST
- @babel/traverse 对AST节点进行递归遍历,生成一个便于操作、转换的path对象
- @babel/generator 将AST解码生成js代码
- @babel/types 通过该模块对具体的AST节点进行进行增、删、改、查
新建 drop-console.js :
const parser = require('@babel/parser')
const traverse = require('@babel/traverse').default
const generator = require('@babel/generator').default
const t = require('@babel/types')
module.exports=function(source){
const ast = parser.parse(source,{ sourceType: 'module'})
traverse(ast,{
CallExpression(path){
if(t.isMemberExpression(path.node.callee) && t.isIdentifier(path.node.callee.object, {name: "console"})){
path.remove()
}
}
})
const output = generator(ast, {}, source);
return output.code
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
使用:
const path = require('path')
module.exports = {
mode:'development',
entry:path.resolve(__dirname,'index.js'),
output:{
filename:'[name].[contenthash].js',
path:path.resolve(__dirname,'dist')
},
module:{
rules:[{
test:/\.js$/,
use:path.resolve(__dirname,'drop-console.js')
}
]
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
注:在webpack4中已经集成了去除 console 功能,在 minimizer 中可配置 去除 console
# webpack-dev-server的原理是什么?
webpack-dev-server启动了一个使用 express 的 Http 服务器,这个服务器与客户端采用 websocket 通信协议,当原始文件发生改变,webpack-dev-server 会实时编译。
webpack-dev-server 伺服的是资源文件,不会对 index.html 的修改做出反应
webpack-dev-server 生成的文件在内存中,因此不会呈现于目录中,生成路径由 content-base 指定,不会输出到 output 目录中。
默认情况下: webpack-dev-server 会在 content-base 路径下寻找 index.html作为首页
webpack-dev-server 不是一个插件,而是一个web服务器,所以不要想当然地将其引入
# 什么是babel-preset-env,babel-plugin-transform-runtime和babel-polyfill?
babel-preset-env:
preset-env 的首要作用,不是帮我们把 ES6+ 代码转成 ES5.它的首要作用是认读 ES6+ 代码。在使用preset-env之前,babel是无法认识ES6+代码的,运行时会报Token错误。在使用preset-env之后,babel才能认识这些代码语法,并将它们抽象出AST树。
其次的作用,才是帮我们转码代码。babel preset说白了,就是一大堆babel plugin的集合。babel的一切转码功能都是靠插件完成的。当然,插件要发挥作用,离不开babel本身的AST抽象能力。也就是babel为插件提供了AST能力,而插件利用该能力,创建/修改AST。
babel-plugin-transform-runtime:
这是一个babel插件,使用这个插件的同时,必须同时安装@babel/runtime这个包。
它有两个作用:
- 将 preset-env 所产生的 helpers 函数提出到一个独立文件中,从而减少代码量
- 建立运行时沙盒,避免全局污染
babel-polyfill:
这个包是一个纯运行时的包,不是babel插件。它的作用是直接改写全局变量,从而让运行环境支持经过present-env转码后的代码。
大部分情况下,preset-env 转码后的代码可以直接使用,但是在涉及到基于 generator 实现的语法时,例如 for...of 语法,则必须引入 regenerator-runtime,因为转码后的代码会生成 regeneratorRuntime 这个全局变量,而 @babel/polyfill 引入了 core-js 和 regenerator-runtime/runtime 两个包。所以每次你安装完 @babel/polyfill 之后,它都会提示你,不要在用它了,直接用 core-js 和 regenerator-runtime/runtime 就好了。所以,虽然我这里说 @babel/polyfill,实际上,大部分情况下,它是指 core-js。
# 说说对 Vite 的理解和 Vite 的实现原理
Vite 是一个基于 ES 模块的开发服务器和构建工具,专为现代前端开发而设计。它的目标是提供快速的冷启动、按需编译和热模块替换等功能,以提供更好的开发体验。
Vite 的实现原理主要基于两个关键点:ES 模块和开发服务器。
ES 模块:Vite 利用了浏览器原生支持的 ES 模块特性。在开发过程中,Vite 不会像传统的打包工具一样将所有代码打包成一个或多个捆绑文件。相反,它会将每个单独的模块作为一个独立的文件提供。这样做的好处是可以避免整体打包的开销,使得开发过程更快速。
开发服务器:Vite 使用自己的开发服务器来提供开发环境。当您启动 Vite 时,它会在后台运行一个服务器,拦截浏览器对模块的请求。当浏览器请求一个模块时,Vite 会根据模块的路径动态地构建和返回该模块的内容。这种按需编译的方式使得只有在需要时才会编译相关的模块,从而加快了开发过程。
在开发过程中,Vite 还使用了 HMR(热模块替换)技术,使得在修改代码后,只需要替换相应的模块,而不需要刷新整个页面。这样可以实现非常快速的代码更新和实时预览。
总结起来,Vite 的实现原理可以概括为:利用浏览器原生的 ES 模块特性,按需编译和提供模块,配合开发服务器和 HMR 技术,实现快速的冷启动、按需编译和热模块替换等功能,从而提供更好的开发体验。
# Vite 开发模式和生产模式的区别
在 Vite 中,开发模式和生产模式有一些区别,主要体现在以下几个方面:
开发服务器:在开发模式下,Vite 使用自己的开发服务器,该服务器提供了许多开发相关的功能,例如快速的冷启动、按需编译和热模块替换(HMR)。它会在后台运行,并在修改代码后实时更新页面,提供实时预览。而在生产模式下,您需要使用 Vite 的构建命令将应用程序打包成优化的静态文件,然后将这些文件部署到生产环境的服务器上,不再需要 Vite 的开发服务器。
构建和优化:在开发模式下,Vite 不会进行完整的打包和优化,而是按需编译和提供模块。这样可以提高开发过程中的构建速度。而在生产模式下,Vite 会执行更彻底的打包和优化,将应用程序及其依赖项打包成更小、更高效的静态文件。这些文件通常会进行代码压缩、文件合并、资源优化等处理,以提供更好的性能和加载速度。
环境变量:在开发模式和生产模式下,您可以通过 Vite 的配置文件或命令行选项设置环境变量。这些环境变量可以用于在不同环境中配置不同的行为,例如 API 地址、调试标志等。在开发模式下,您可以轻松地切换环境变量,并且它们通常会自动热更新。而在生产模式下,您需要在构建过程中指定要使用的环境变量,并将其固定在生成的静态文件中。
总的来说,Vite 的开发模式和生产模式的区别在于开发模式下提供了更快速的开发体验和实时预览,而生产模式下则进行了更彻底的打包和优化,生成适用于生产环境的优化静态文件。
# Webpack 和 vite 有什么区别
Webpack和Vite是两个常用的前端构建工具,它们在一些方面有一些区别,下面是它们的一些主要区别:
构建速度:Vite在开发模式下具有更快的冷启动和热模块替换(HMR)速度。这是因为Vite利用了浏览器原生的ES模块特性,按需编译和提供模块,而不是像Webpack那样进行完整的打包。这使得Vite在开发过程中能够更快地构建和更新模块,提供更快的开发体验。
开发服务器:Vite使用自己的开发服务器,在开发模式下提供实时预览和快速的HMR。而Webpack通常需要借助webpack-dev-server或webpack-dev-middleware等插件来提供类似的开发服务器功能。
配置:Webpack的配置文件相对复杂,需要手动配置各种loader、plugin和optimization等选项来处理不同类型的文件和优化构建过程。而Vite的配置相对简单,大部分情况下不需要额外配置,它会根据文件类型自动选择合适的插件和优化策略。
生态系统:Webpack是一个非常成熟和强大的构建工具,拥有庞大的生态系统和丰富的插件支持,可以处理各种复杂的构建需求。Vite相对较新,生态系统相对较小,但它的发展速度很快,并且在Vue.js等框架中得到了广泛的应用和支持。
生产模式:Webpack在生产模式下提供更全面的打包和优化功能,可以生成高度优化的静态文件。Vite在生产模式下也能进行打包和优化,但相对于Webpack而言,Vite更加专注于开发体验和快速构建,因此在一些复杂的构建需求上可能需要额外的配置和插件支持。
总的来说,Webpack是一个功能强大且成熟的构建工具,适用于处理各种复杂的构建需求。Vite则专注于提供快速的开发体验和现代前端框架的支持,特别适合用于快速原型开发和中小型项目。选择使用哪个工具取决于项目的具体需求和个人偏好。
# 说一下 vite 相对与 webpack 的优化
Vite相对于Webpack在性能和开发体验上进行了一些优化,下面是一些Vite相对于Webpack的优化点:
快速的冷启动:Vite利用了浏览器原生的ES模块特性,按需编译和提供模块,避免了完整的打包过程。这使得Vite在启动项目时可以更快地构建和启动开发服务器,减少了冷启动的时间。
快速的热模块替换(HMR):Vite通过浏览器原生的ES模块特性实现了更快速的HMR。它可以在开发过程中快速更新修改的模块,而无需重新加载整个应用程序。这提供了更快的开发体验,可以立即看到代码更改的效果。
按需编译:Vite只编译需要的模块,而不是像Webpack那样对整个项目进行完整的打包。这减少了不必要的编译时间,特别是在大型项目中,只有修改的模块才会重新编译,提高了开发效率。
原生ES模块支持:Vite直接使用浏览器原生的ES模块加载机制,而不需要进行模块转换和打包。这减少了构建过程中的处理和转换时间,提供了更快的构建速度。
静态资源优化:Vite在生产模式下对静态资源进行了优化,例如自动压缩代码、提供按需加载和预加载等功能。这有助于减小生成的静态文件的大小,提高应用程序的加载速度和性能。
需要注意的是,Vite并不是取代Webpack,而是在开发过程中提供了更快速的开发体验。在生产环境中,Vite会使用Rollup等工具进行完整的打包和优化,以生成适用于生产环境的静态文件。因此,在一些复杂的构建需求和生态系统支持方面,Webpack仍然是一个更全面和成熟的选择。
# Webpack、Vite、Rspack 性能对比
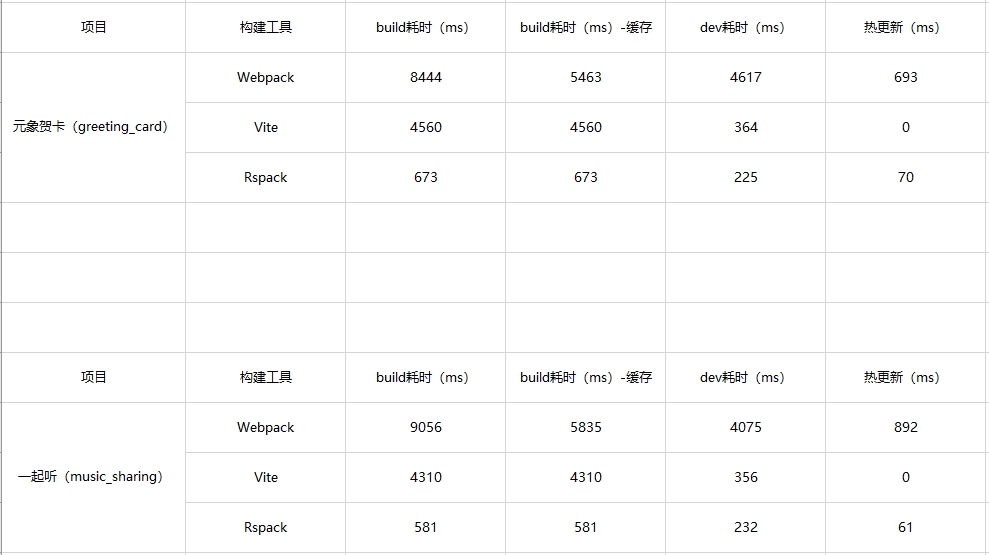
参考文章:
吐血整理,再来一打Webpack面试题 (opens new window)
@babel/preset-env, @babel/polyfill和@babel/plugin-transform-runtime (opens new window)
← react进阶面试题 性能优化面试题 →